
Category: python
You are viewing all posts from this category, beginning with the most recent.
New Instructor Dashboard
I’ve been working on a new instructor dashboard the last week using Plotly + Dash. Its taken a while to wrap my head around the declarative style, and to learn the ins and out of plotly. But I’m getting there. Let me know if you want a closer look and would like to give me feedback! In the meantime here is a preview.

adventures with flask-cors
-
I want people to be able to write and host the static parts of any book on any server. You can think of each page in a book as its own single page application.
-
I want to provide back-end services so that students using any book hosted anywhere can save their programs and answers to quizzes etc.
-
I want to continue to gather research data on how students learn computer science.
-
I want to make the registration and login process as easy as possible.
Since the static parts can be hosted anywhere (including a site like interactivepython.org) The interactive parts are going to involve making cross-domain XMLHttpRequests (xhr). Of course the first thing that happens when you have a page hosted on static-site that makes an xhr request to ajax-server is that you get an error. Browsers and sites work together to disallow cross-domain requests to prevent a variety of nasty behaviors. But, there are many times (wlike now) when you have a legitimate reason for doing this. So, the w3c created the Cross Origin Resource Sharing (CORS) standard to help developers get around this. Cory Dolphin has created an excellent plugin for Flask developers called Flask-CORS. The plugin is a great example of the brilliant design behind Flask and in fact the entire WSGI stack.
The Really Simple Approach
The first thing you find when you start googling about this problem is that there is a seemingly simple solution. If you have control over your AJAX response you simply need to add an HTTP header Access-Control-Allow-Origin: * problem solved. Now everyone in the world can make xhr requests to your server and use the results in their page.
Adding a header is pretty simple in Flask. All you need to do is use response.headers.add("Access-Control-Allow-Origin", "*" Problem solved, moving right along to the next programming challenge.
Or maybe not. Minutes later you realize that this is not all that great because you have decorated some of your requests to require a login. That wont be a problem if the static page is served from the same domain because you will automatically get the session cookie, and the Flask-Security extension will eat that cooking and validate things for you. BUT if your static page is not served from the same domain you will not even get the session cookie. Oh Bother. But you also have a second problem. You have probably violated the CORS specification without even meaning to. Really, if I had to read the spec for every web standard I wanted to use I would seriously think about changing careers. But, here is the important part you may not return a CORS header unless the request contains an origin header! Chances are you tested you change with a quick curl call to your endpoint, saw the Access-Control header and were happy. But you sure didn’t give it an origin header on the request when you did that. So to summarize, we have two problems we need to solve:
-
We want to incorporate authentication into our cross origin strategy.
-
We want to be good citizens and follow the spec.
The Smart Approach
The smart approach is to use a nice extension where other people have figured this out, and presumably followed the specification. Enter Flask-CORS. You can enable CORS support with a simple decorator @cross_origin This will automatically add the Access-Control-Allow-Origin: * to responses. As long as your test request includes an Origin. If you are like me you will forget that part, and then wonder why the extension must not be working. So this solves problem 2.
To solve problem 1 here is a snippet of code that works just fine.
@ajax.route('/ajax/page')
@login_required
@cross_origin(supports_credentials=True)
def test():
return jsonify({'foo':'bar'})
The above responds to the url /ajax/page I have all of my API calls in an ajax blueprint with ajax as part of the url. I’m requiring that the user is logged in before I allow them to access this endpoint. I also want it to be allowed cross origin. This is where the parameter to the @cross_origin comes into play. Supports credentials sets up the CORS response to return an additional CORS header: Access-Control-Allow-Credentials: "true". For one final twist, you need to know that when you have supports_credentials=True you may NOT set Access-Control-Allow-Origin: * You need to be specific and set the origin to the origin that comes in the request headers. To Make this work and try it out from the client side, here is a bit of HTML/Javascript.
<button onclick="corsTest();">TestCORS</button>
<script>
function corsTest() {
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
xhr.onload = function () {
alert(xhr.responseText);
}
xhr.onerror = function () {
alert("error");
}
xhr.open("GET", "http://example.com/ajax/page", true)
xhr.send()
}
</script>
Note that you need to set xhr.withCredentials in order for your session cookie to be sent along. By default cookies are NOT sent with cross origin requests.
Now, I may end up adding more to this as I discover the intricacies of so called “Non-Simple” requests. That is requests beyond simple GET and POST, as I work on moving my API toward a RESTful API which uses PUT and others. This will nodoubt enlighten me about preflighted requests. Which I can only assume means something different than sitting around in an airport bar waiting for your flight to be called.
There is a lot more detail and background on using CORS at the following two sites:
writing a runestone lab the easy way
As part of the grand reorganization of the various tools and software associated with the Runestone Interactive project I am planning to also write a series of tutorials to help people get started. The major aspects of this reorganization are discussed in detail in the Project Roadmap, but for the sake of some context I can summarize the major efforts as follows:
-
Separate the distribution and development of writing tools from the server.
-
Make a pip installable runestone package.
-
Remove the interconnectedness between the components and Sphinx. In other words support the user of runestone tools in environments like Markdown, and even wysiwyg html editors.
-
-
Re-architect the server side focusing on services for the writing tools
-
Create an authentication service that supports CORS for cross domain AJAX use.
-
Create a standard REST API for logging and storing student data
-
-
Create a web application (or integrate with another) for grading
Since I just completed Part 1.1 I thought it was a good time to talk about how easy it is for you to now use the runestone tools for creating a lab for your students, or lecture notes and presentation materials for your class.
Getting Started
The major steps in getting started are
-
Installing Python
-
Installing the runestone tools
-
Building your first lab
Install Python
-
If you are on a Mac you are already done with this step.
-
If you are on Windows you will need to go to Python.org and download Python3.x. The windows installer is a typical installer and you can just click your way through it.
If you are an advanced Python user you may want to may want to create a virtualenvironment for this project but it is not a requirement.
If you are on Windows you may want to edit your PATH environment variable following the instructions here. Again, mac users can ignore this.
Installing the Runestone Components
You are going to need to use the command line for the rest of this tutorial, so start up a Terminal (/Applications/Utilities on a Mac or run PowerShell or cmd.exe on Windows) I will repeat myself here. These commands need to be run from the command line, not from the Python shell.
Run the pip command
$ pip install runestone
Or on Windows if you have not modified your PATH try:
C:\\Python34\Scripts\pip.exe install runestone
From now on I’m only going to give the Mac way of running the commands. If you are on windows you will need to add C:\\Python34\Scripts to the beginning of the command and add .exe to the end.
You can watch as a lot of text goes scrolling by. But as long as you don’t get any errors you should be good to go. You only need to do these first two steps once. Once you have installed Python and runestone you will not have to do it again.
Starting your first Runestone Project
Here is a session of me on my computer creating a simple project.
$ mkdir mynewproject
$ cd mynewproject
$ runestone init
This will create a new Runestone project in your current directory.
Do you want to proceed? [Y/n]: y
Next we need to gather a few pieces of information to create your configuration files
Project name: (one word, no spaces): myhello
path to build dir [./build]:
require login [false]:
URL for ajax server [http://127.0.0.1:8000]:
Your Name [bmiller]: Brad Miller
Title for this project [Runestone Default]: My Hello World
Log student actions? [True]: False
Done. Type runestone build to build your project
At this point you will have the following files and folders:
mynewproject/
_static/
_sources
_templates
conf.py
pavement.py
-
The
_staticfolder is for things like images or javscript files. -
The
_sourcesfolder is where you will put your own writing. To start with there are a couple of examples files for you. -
The
_templatesfolder is for styling. There is a default set of templates that match the runestone interactive look and feel. That is a good thing to start with. Once you become more familiar with the system you may want to customize the templates or even make your own. -
The
conf.pyfile is used by Sphinx, and contains information from some of the questions you answered when you initialized your project. -
The
pavement.pyfile is used for building and setting build parameters.
All of these files are important, and you should not delete any of them.
Next run runestone build This command will create a build/mynewproject folder with an index.html file in it. If you want you can now run runestone serve and then go to your browser and open up the following URL http://localhost:8000/index.html Yay! You have a webpage. Feel free to explore a bit to get an idea about some of the components you can use in your lab.
Writing your Own Lab
OK, lets edit _sources/index.rst Initially it looks like this:
=====================
This Is A New Project
=====================
SECTION 1: Introduction
:::::::::::::::::::::::
Congratulations! If you can see this file you have probably successfully run the ``runestone init`` command. If you are looking at this as a source file you should now run ``runestone build`` to generate html files. Once you have run the build command you can run ``runestone serve`` and then view this in your browser at ``http://localhost:8000``
This is just a sample of what you can do. The index.rst file is the table of contents for your entire project. You can put all of your writing in the index, or as you will see in the following section you can include additional rst files. those files may even be in subdirectories that you can reference using a relative path.
The overview section, which follows is an ideal section to look at both online and at the source. It is pretty easy to see how to write using any of the interactive features just by looking at the examples in ``overview.rst``
SECTION 2: An Overview of the extensions
::::::::::::::::::::::::::::::::::::::::
.. toctree::
:maxdepth: 2
overview.rst
SECTION 2: Add more stuff here
::::::::::::::::::::::::::::::
You can add more stuff here.
If you are not familiar with markup languages, this file should still be quite readable to you, and you can probably easily guess what most things do. Runestone uses a markup language called restructuredText. There is a very nice, short tutorial here.
To give you an idea of what you see in the example above, the section that starts with .. toctree:: is called a directive and it creates a table of contents for you. the maxdepth part sets the table of contents to show sections and subsections. And the line with overview.rst indicates that it is a file that should be included in the overall web page. More on all of this later. Our first task is simply going to be to wipe everything out, and start over. Using a plain text editor change index.rst to look like this:
=============
My Sample Lab
=============
Part 1: Turtle Graphics
=======================
In this section we will do the following:
* Create a turtle
* Make the turtle draw a box
.. activecode:: turtle1
import turtle
timmy = turtle.Turtle()
for i in range(4):
timmy.forward(100)
timmy.right(90)
Now it is your turn. Can you modify the program to make timmy draw an octagon instead of a square?
Now save the file and rerun the runestone build command. Everything should build without a problem and you can now run runestone serve and open up http://localhost:8000 from your browser. Notice that you can change the program and rerun it right from your browser.
It is probably obvious that you can create headings and subheadings. Unordered lists are created using * and the runnable code examples are created by the .. activecode:: directive. The name turtle1 must be unique on the webpage, other than that it is not used for too much at this point. The rest of the activecode directive contains plain old python code, but it must be indented to line up with the a in activecode. All indented lines are included as the body of the activecode directive, regular text processing starts at the first unindented line.
There you have it. You have created a very nice little lesson without a lot of hassle. The Runestone and Sphinx tools take care of all of the formatting for you!
Giving Students Browser Access to the Lab
If you have your own webpage hosted on a school server that you normally use for class you can make your Lab available to the students by simply taking the folder mynewproject inside the build folder and putting that on your website. The folder is self contained and can be hosted on any web server.
If you know the IP Address of your own computer and you simply want to give let students bring up the webpage from your computer you can do that too. For example, lets suppose you know that your IP address is 10.0.0.23 Your students can get everything they need from http://10.0.0.23:8000/index.html
Coming Soon
There are many free web hosting solutions out there and you can also choose one of them and upload your project folder for hosting there. I’ll cover at least one of them in another tutorial. In fact I think I see a whole series of tutorials in the future on topics such as:
-
Making an online quiz for class
-
Making a lecture or presentation
-
Hosting your lab or quiz on github pages or another online service
-
Using your lab with runestone services
easy publishing with runestone interactive
During my January travels, I also converted this blog from tubmlr, which had been frustrating me for a while, to Octopress, with which I have been very happy. Nothing like hacker level control of your own blog. But more, than just the switch in tools, the move to Octopress inspired me to make it easier for people to publish small or large works using the Runestone tools.
Yesterday, at the Learning @ Scale conference we demoed this new capability. See [the demo here](<http://runestoneinteractive.org/LearningAtScale). To make it super easy to publish:
-
Lecture slides
-
Demonstrations
-
A Tutorial
-
Lab Instructions
-
In class exercises
-
A short module on your favorite topic not covered elsewhere
-
An entire book
Building
You can simply follow the instructions at this new repository: github.com/RunestoneInteractive/RunestoneTools. In a nutshell:
-
Install Sphinx, paver, and paverutils using pip.
-
Clone the repository
-
Edit the index.rst file in source, and add any additional rst files you may want, depending on how complex your project is.
-
run
paver build
Deploying
Now you have a choice. In the build directory you have a nice self contained set of html files, these files are set up to make use of the runestone server invisibly in the background. The static html can be served from any web server. Just drop in the build directory and you are ready to serve. OR, you can now host and deploy your project using GitHub Pages. To host on github pages you need to do three things.
-
Create an empty repository in your github account.
-
run
paver setup_github_pagesand paste in the URL of the new account. -
run paver deploy
Now your pages will be available at: http://youraccount.github.io/YourRepo
If you want to host these pages behind a custom domain name, you can follow the instructions on github for doing so. Hint: Its really easy.
I hope this new capability will inspire lots of people to give these tools a try. I also hope that we can build a repository of resources built with the tools, so that we can all share our teaching ideas. Stay tuned for more on that.
Caveats
All of the features, activecode, codelens, assessment questions, parson’s problems, and more work just fine. The major thing that will not work (yet!) is the login/logout. I need to rework our authentication system in order for this to work. This will for sure need to happen before the end of summer.
runestone interactive announces new editions of interactive textbooks
Today I'm really pleased to announce that have launched version 2.0 of our interactive computer science textbooks:
- How to Think Like a Computer Scientist: Interactive Edition 2.0 (CS 1)
- Problem Solving with Algorithms and Data Structures using Python (CS 2)
We first launched these books on our interactivepython.org website in May of 2012, after around a year of private testing in the classroom. Since then we have had 1.3 million page views by a quarter of a million unique visitors. Daily, we get around 2,000 unique visitors. Not bad for a site with zero dollars for an advertising budget.
What Makes these Books Unique?
These books are unique because they are interactive. We have developed a set of authoring tools that make it really easy to write an interactive textbook with many interactive features. We call these the Runestone tools. Some of the interactive features that are possible include:
- Activecode: Using a Javascript implementation of Python you can run and modify the examples in the textbook right in the book. No server connection is required since it is based on javascript and runs right in the browser.
- Codelens: Using the amazing power of the pythontutor.com tools you can step through examples one line at a time, forward and backward. While you are stepping through the code you can see variables and other data structures change values.
- Parsons Problems: For beginning programmers Parson's problems are like refrigerator magnet poetry. You can provide your students with the statements needed to write a program, but they must put the statements in the correct order.
- Inline Quizzes: Each section of the book contains some inline quizzes that allow students to check their understanding of the material. The quizzes have different feedback for each correct or incorrect answer that try to point students in the right direction.
- Online Homework: At the end of each chapter are programming assignments. In this new edition we have provided the answers to the odd numbered questions, and discussion forums for students to exchange ideas or ask questions about the homework problems. As an instructor, you can grade your students programs on one convenient page.
- Highlighting This is another much requested new feature. Students can highlight text using the mouse and the highlights magically reappear on any supported browser. In addition we will remember the students last location in the book and offer to return them to that position when they return.
- There are many other features but the best way to understand what we are doing is to actually have a look at our overview page, which shows everything I have mentioned here and a lot more in action.
Over this past year we have discovered that we serve two different audiences with these books.
- Instructors looking for a textbook to use in their own course
- People who are interested in teaching themselves some computer science and have found our books through google search, the Python wiki, or some other word of mouth source.
Textbooks as a Service
When we launched the site last year we decided to not only provide the books free and open for anyone who wanted to read them, but also as a service for instructors who wanted to have their own custom copy of the book where they could track their students progress, review their answers to quizzes, and grade their students homework. If you want to use our books in your class you are welcome to do so. You have two options:
- You can use a copy of either book as is with the order of the chapters just as they are on the books linked to above.
- You can try our custom interface where you can mix and match chapters from both books to create your own custom textbook.
Once you have created your own course then you will be able to see the assignments your students have completed right in the textbook. I find this to be very valuable as an instructor. For example if I have assigned the students to read and do the quizzes for a particular section, I can simply go to the quiz question and click on the 'Compare Me' button. As an instructor I will see a summary of the answers my students gave, as well as the details of the answers that each student tried.
Supporting the Independent Learner
Perhaps the biggest surprise of this project is the number of people that have found one of the books through google, and are simply teaching themselves to program. We are hopeful that some of the new features we have added will help foster a community of learners so that people just learning to program can talk to others in the same situation. Some things we hope are particularly helpful include:
- Answers to odd numbered questions. This was probably the number one request I got through email all last year. How do I know if I did it right? We decided to risk it and provide the answers, but only to the odd numbered problems. In addition a student must try to answer the problem at least once before the answer becomes "unlocked"
- Discussion threads for homework problems. Again this may seem like a risky move where students can just publish their answer and others can copy. But, what we are hoping for is that students will see that there are many ways to get to the "right answer" There are different approaches and programming styles that can be used to solve the same problem.
- Compare Me Although we aren't sure about the title on the button, the idea is that after answering one of the quiz questions a learner can check on their overall 'grade' for all quiz questions, and see how their answer compared to all the other learners. We haven't gone so far as to give out badges, but we think this is a nice intermediate approach.
The Runestone Tools
The books above were built using our Runestone Interactive toolkit. These tools are freely available on github. If you want to write your own interactive book, or even just use the tools to create some interactive labs for your students you are welcome to do so. You can write your materials in an easy to use markup language called restructuredText and add examples or quizzes using very simple tags. Complete documentation for our extensions to restructuredText is provided on the website. In addition to our own books, the team at Harvey Mudd College has published CS for All another introductory textbook using our tools. I know of at least two other books in progress!
If you are interested in following our development or getting involved You can do so in several ways:
- Twitter, follow iRunestone
- Facebook, facebook.com/RunestoneInteractive
- Google Groups
Acknowledgements
I am grateful to the many people who have provided us with feedback over the last year. And I am especially grateful to the ACM SIGCSE social projects committee for providing me with a special projects grant that allowed me to work with a student (Isaac Dontje Lindell) this summer. He did a ton of work and will be graduating next year. You should hire him. In addition this project relies on many open source components which I will mention and link to below.
- The original text for How to Think Like a Computer Scientist comes from Allen Downey, Jeff Elkner and Chris Meyers. We have modified it a lot, but without a starting point for us to experiment with our interactive ideas this project never would have taken off.
- The Problem Solving with Algorithms and Data Structures text is published as a paper textbook by Franklin Beedle and Associates. Without the forward thinking of Jim Leisy this book would be stuck. Thankfully Jim freed us to use the text in an interactive form online.
- Mark Guzdial, Barbara Ericson and the rest of the CSLearning4U research group at Georgia Tech have provided questions, assessments, and many other features and ideas.
- The Activecode examples are made possible by skulpt
- The Codelens examples are made possible by Philip Guo and his pythontutor.com
- The look and feel of the book is based on the bootstrap templates
- The system that builds the website from source is called Sphinx and is really the backbone of the system that allows us to write our interactive extensions.
- Ville Karavirta wrote the original js-parsons library and Mike Hewner integrated it into the Runestone Tools.
making python3 my default
I'm finally there. After a long time of writing books using Python 3, and teaching in Python 3 on a daily basis, I'm finally at the point where I'm changing my work environment to use Python 3 by default.
Here are the signs that convinced me it was time:
- The release of Pillow to provide PIL functionality!
- Django 1.5
- IPython and IPython notebook are fully supported -- I Love IPython Notebook
- matplotlib !!
- Sphinx, Jinja, SQLAlchemy, and many others are supported. See: https://python3wos.appspot.com/
There are a couple of projects that I use a lot that are not yet on Python3 (web2py) but I'm not going to let that stop me.
It turns out to be pretty easy to get yourself up and running on all of this stuff with Python 3. I'm on a Mac running 10.8.3. The first and most important step is to get a working version of pip for Python3. First you need to install distribute.
curl -O http://python-distribute.org/distribute_setup.pyThis will install easy_install in your Python home, but go one more step and install pip.
curl -O https://raw.github.com/pypa/pip/master/contrib/get-pip.pyThis will create a pip in your /Library/Frameworks/Python.framework/Versions/3.3/bin directory.
From there you can begin pip installing pretty much everything you need!
From my history today as I was setting everything up:
10393* pip3 install ipython
10409* pip3 install numpy
10410* pip3 install matplotlib
10429* pip3 install tornado
10430* pip3 install pyzmq
10455 pip3 install Sphinx
If you are on a Mac you will need to use easy_install to install one thing, for IPython. For some reason pip installing the readline library puts it too late in the load path to work with IPython, so you need to use easy_install-3.3 readline to get the history in IPython working just right.
Finally, you will want to add the Python 3 bin directory to your PATH. Edit your .bashrc or .zshenv file. Note that the following puts the Python 3 bin directory at the front of your PATH, making it the default when you type pip, python, or ipython. If you need to revert back to python2.7 for some task you will need to be explicit about it.
export PATH=/Library/Frameworks/Python.framework/Versions/3.3/bin:$PATH
Easy! You were expecting this to be a long and arduous process fraught with hacks and silly edits to config files. Nope, just a few basic commands. I take this as the final sign that Python 3 is here and ready to be your day to day Python.
to infinity and beyond
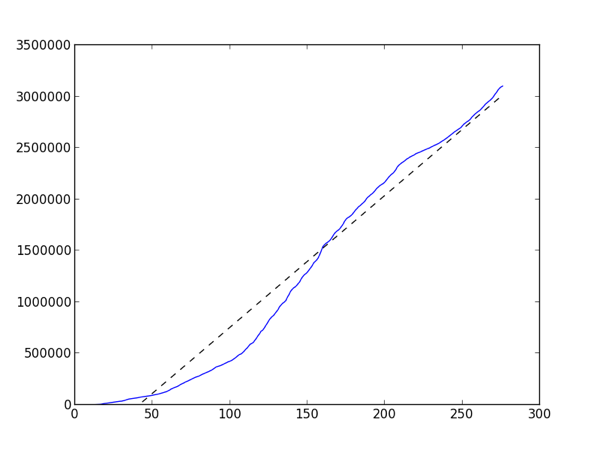
We passed 3 million entries in our log data for InteractivePython.org which got me to wondering about how we are growing. The site has been live for 275 days. You can really see how the site took off after day 100, which makes sense because that was bout the time fall classes started around the country. The tiny plateau between day 225 and 250 corresponds to Christmas/winter break for most schools, and now that Spring semester is in full swing it looks like the slope has gotten steeper again.
The dotted line is the linear best fit line with a slope of 12,836.7. Even if our log database is not growing exponentially thats an impressively steep slope.
And just because this is all about Python and education, here's the Python code that created the graph. I love matplotlib, it is such a powerful tool for quickly looking at your data.
import matplotlib.pyplot as plt
from numpy import polyfit, arange
f = open('bydate','r')
days = f.readlines()
totals = [0]
for d in days:
day,count = d.split('|')
count = int(count)
totals.append(totals[-1]+count)
x = arange(len(totals))
m,b = polyfit(x,totals,1)
print m
plt.plot(x,totals,x,m*x+b, '--k')
plt.ylim(ymin=0)
plt.show()
The data file is simple. One day per line with the date in one column and the number of actions in the other column. Here are the last few days:
2013-02-14 | 24349 2013-02-15 | 17396 2013-02-16 | 12645
everyday python - new blog
I've decided that it will be best to keep my personal blog separate from the new Everyday Python blog project. All of the infrastructure to make the posts interactive just work so much better when I have control of the server and everything else. So You can head over to Everyday Python and click on the Everyday Python link there, or if you want to subscribe to the RSS feed for that project you can use this link.
generating a password - part 1
OK, here is the first installment of the new Everyday Python series. Today I'm just providing a link, as I still have some infrastructure work to get done in order to publish each installment both here and at Runestone Interactive.
introducing everyday python
Everyday Python¶
It is always risky to make your New Years resolutions public, but this is one I’ve
been thinking about for a while now, and so I’m going to go ahead and impose a
measure of accountability on myself by proclaiming this publicly. This week, I’m
starting a series of educational blog posts here, and as a part of my Runestone
Interactive publishing project.
My idea is to publish a series of Python programming projects, aimed at solving
everyday problems, or puzzles. Hopefully these little projects will be interesting
and will give learners motivation to dig into the details of the solutions. I
will provide links to the relevant Python programming constructs and data types in
either of the two interactive books (How to think like a computer scientist:
Interactive Edition , or
Problem Solving with Algorithms and Data Structures using Python) This will let me
focus on the problems, and not the minutia of the language. Lets face it, reading
about all the different possible string methods is not that exciting, but seeing
them in action, and then wondering about what else you might be able to do with
strings is OK.
The great thing about Python is that if you write things in a straightforward
manner its pretty easy to follow even if you don’t know all the details. So, that
is my intention. Write a solution and do it in straightforward Python that
beginners can understand. Each project will appear over several days, and
will likely include some homework related to the project. I’ll provide the solution
in a followup post. In addition, I may refine the solution over the course of
several days introducing more and interesting solutions or more advanced features
of the Python language.
In the back of my mind I am drawing inspiration from the old Communications of the ACM column by John
Bently called Programming Pearls In John’s columns he would feature a particular
problem or algorithm, and present it in a straight forward way, but then he would
refine that solution again and again polishing it until he had an incredibly
elegant solution. It was beautiful because even a novice programmer could
understand what was going on at the start of the article, but would get sucked in
to the beautiful solution and would learn more than they thought possible. While
advanced programmers might chuckle at the initial solutions, even they would have
to admit that they learned something by the end of each column.
I already have a few ideas in mind for the first few projects. I’m going to try
to start fairly easy with some string and list kind of projects, and work my way up
to more complex problems and algorithms, again this is meant to be educational so
that in theory a beginner might read through these posts more or less
chronologically, and learn some computer science along the way.
Click the title to leave a comment.